
124
Прегледи

Последна актуализация на

Една от най-големите грешки за собствениците на нови уебсайтове е да не се вглеждат в техния файл robots.txt. И така, какво е така и защо толкова важно? Имаме вашите отговори.
Ако притежавате уебсайт и се грижите за SEO здравето на вашия сайт, трябва да се запознаете много добре с файла robots.txt във вашия домейн. Вярвате или не, това са смущаващо голям брой хора, които бързо стартират домейн, инсталират бърз уебсайт на WordPress и никога не си правят труда да правят нищо с файла си robots.txt.
Това е опасно. Неправилно конфигуриран файл robots.txt може всъщност да унищожи SEO здравето на вашия сайт и да повреди всички шансове, които може да имате за увеличаване на трафика си.
Най- Robots.txt файлът е подходящо наречен, тъй като по същество това е файл, който изброява директиви за роботи в мрежата (като роботи в търсачката) за това как и какво могат да обхождат на вашия уебсайт. Това е уеб стандарт, следван от уебсайтове от 1994 г. насам и всички основни уеб сканери се придържат към стандарта.
Файлът се съхранява в текстов формат (с разширение .txt) в основната папка на вашия уебсайт. Всъщност можете да видите файла robot.txt на всеки уебсайт само като напишете домейна, последван от /robots.txt. Ако опитате това с groovyPost, ще видите пример за добре структуриран файл robot.txt.
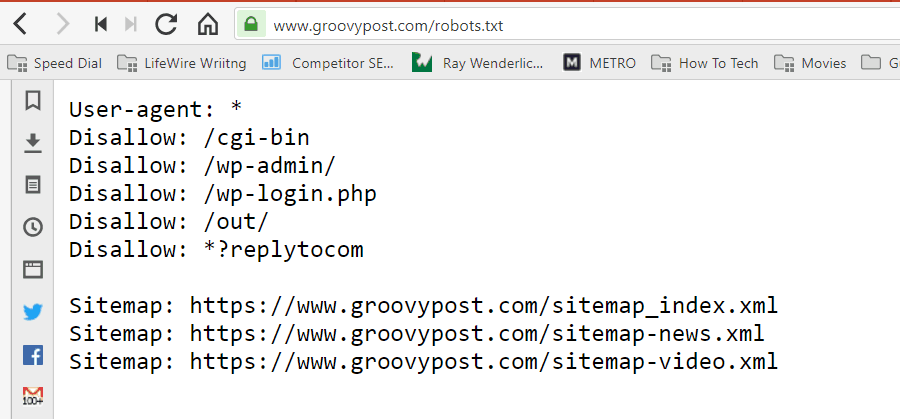
Файлът е прост, но ефективен. Този примерен файл не прави разлика между роботи. Командите се издават на всички роботи чрез използване на Потребителски агент: * директива. Това означава, че всички команди, които го следват, се прилагат за всички роботи, които посещават сайта, за да го обхождат.
Можете също така да определите конкретни правила за конкретни уеб сървъри. Например, можете да разрешите на Googlebot (уеб сървър на Google) да обхожда всички статии на вашия сайт, но може да искате да забранете на руския уеб браузър Yandex Bot да обхожда статии на вашия сайт, за които има пренебрежителна информация Русия.
Има стотици уеб сканери, които търсят в интернет информация за уебсайтове, но 10-те най-често срещани, за които трябва да се притеснявате, са изброени тук.
Като вземем примерния сценарий по-горе, ако искате да разрешите на Googlebot да индексира всичко на вашия сайт, но сте искали блокирайте Yandex да индексира съдържанието на вашите руски базирани статии, добавете следните редове към robots.txt файл.
Потребителски агент: googlebot
Disallow: Disallow: / wp-admin /
Дезактивиране: /wp-login.php
Потребителски агент: yandexbot
Disallow: Disallow: / wp-admin /
Дезактивиране: /wp-login.php
Дезактивиране: / Русия /
Както можете да видите, първият раздел блокира само Google да обхожда вашата страница за вход в WordPress и административни страници. Вторият раздел блокира Yandex от същия, но също така и от целия район на вашия сайт, в който сте публикували статии със антируско съдържание.
Това е прост пример за това как можете да използвате Забрана команда за контрол на конкретни уеб-роботи, които посещават вашия уебсайт.
Disallow не е единствената команда, до която имате достъп във вашия файл robots.txt. Можете също да използвате някоя от другите команди, които ще насочат как робот може да обхожда вашия сайт.
Имайте предвид, че ботовете ще само слушайте командите, които сте предоставили, когато посочвате името на бота.
Често срещана грешка, която хората правят е забраняването на области като / wp-admin / от всички ботове, но след това посочват раздел за googlebot и забраняват само други области (като / около /).
Тъй като ботовете следват само командите, които сте посочили в техния раздел, трябва да рестартирате всички тези команди, които сте посочили за всички ботове (използвайки * user-agent).
Имайте предвид, че robots.txt има за цел да помогне на законните ботове (като ботове в търсачките) да обхождат по-ефективно вашия сайт.
Има много злобни сканери, които обхождат вашия сайт, за да правят неща като остъргват имейл адреси или да откраднат съдържанието ви. Ако искате да опитате и да използвате файла си robots.txt, за да блокирате тези сканери да не обхождат нещо на вашия сайт, не се притеснявайте. Създателите на тези сканери обикновено игнорират всичко, което сте поставили във файла си robots.txt.
Намирането на търсачката на Google да обхожда възможно най-качествено съдържание на уебсайта Ви е основна грижа за повечето собственици на уебсайтове.
Google обаче харчи само ограничено обходете бюджет и честота на обхождане на отделни сайтове. Коефициентът на обхождане е колко искания в секунда Googlebot ще отправя към вашия сайт по време на събитието за обхождане.
По-важен е бюджетът за обхождане - това е колко общи искания ще отправят Googlebot за обхождане на вашия сайт в рамките на една сесия. Google „харчи“ бюджета си за обхождане, като се фокусира върху областите на вашия сайт, които са много популярни или променени наскоро.
Не сте слепи за тази информация Ако посетите Google Инструменти за уеб администратори, можете да видите как роботът обработва вашия сайт.
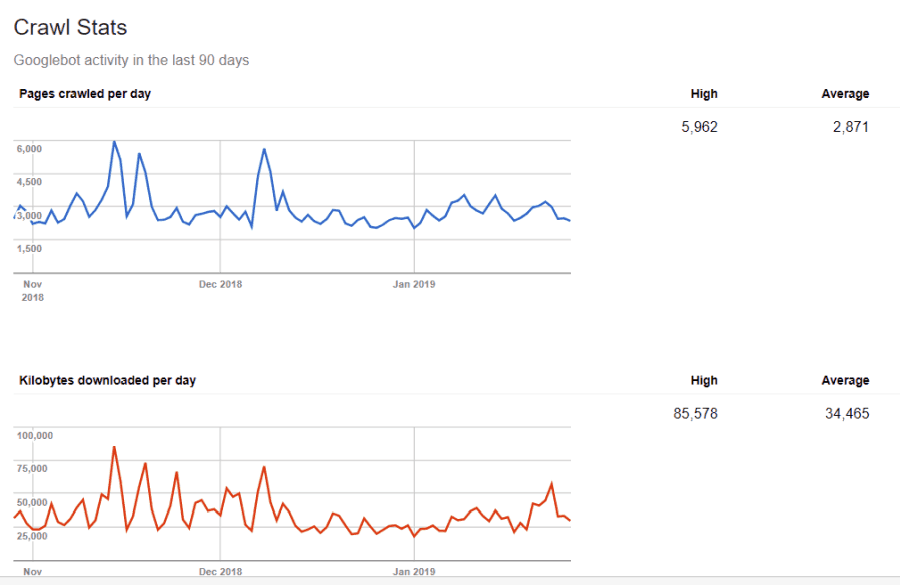
Както можете да видите, роботът поддържа дейността си на вашия сайт доста постоянна всеки ден. Той не обхожда всички сайтове, а само онези, които счита за най-важни.
Защо оставяте на Googlebot да реши какво е важно на вашия сайт, когато можете да използвате файла robots.txt, за да му кажете кои са най-важните страници? Това ще попречи на Googlebot да губи време на страници с ниска стойност на вашия сайт.
Google Инструменти за уеб администратори също така ви позволява да проверите дали Googlebot чете добре вашия файл robots.txt и дали има грешки.
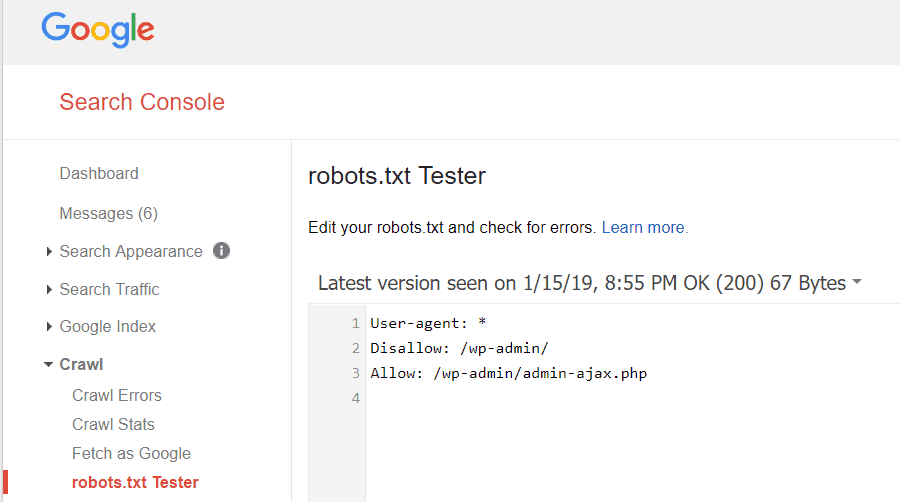
Това ви помага да потвърдите дали сте структурирали файла си robots.txt правилно.
Какви страници трябва да забраните от Googlebot? Добре е SEO на вашия сайт да забрани следните категории страници.
Най-голямата грешка, която правят новите собственици на уебсайтове, е дори да не гледат файла си robots.txt. Най-лошата ситуация може да бъде, че файлът robots.txt всъщност блокира вашия сайт или райони на вашия сайт от изобщо да се обхожда.
Не забравяйте да прегледате файла си robots.txt и се уверете, че е оптимизиран. По този начин Google и други важни търсачки „виждат“ всички страхотни неща, които предлагате на света с вашия уебсайт.
